
Blogeintrag | Web Scraping: Basics, Use Cases and Chalenges
Von Sebastian Zettl am 16.01.2025
Web Scraping and Web Crawling are two terms that most people probably have never even heard of. But both are powerful tools that are used to collect data from the web to help businesses recognize trends, do competitive analysis, but are also at the basis of for search engines to allow them to show you the best possible search results.
In this Blog article I will write at length about Web Scraping and by extension, Web crawling. What they are, all the common uses cases and the associated challenges, technical as well as legal and ethical.
Web Scraping on the other hand is something that is akin to an extension of web crawling. WIth crawling you find websites that are of interest, and you can then use Web scraping software to extract information from the web page and downloading it.
Basics
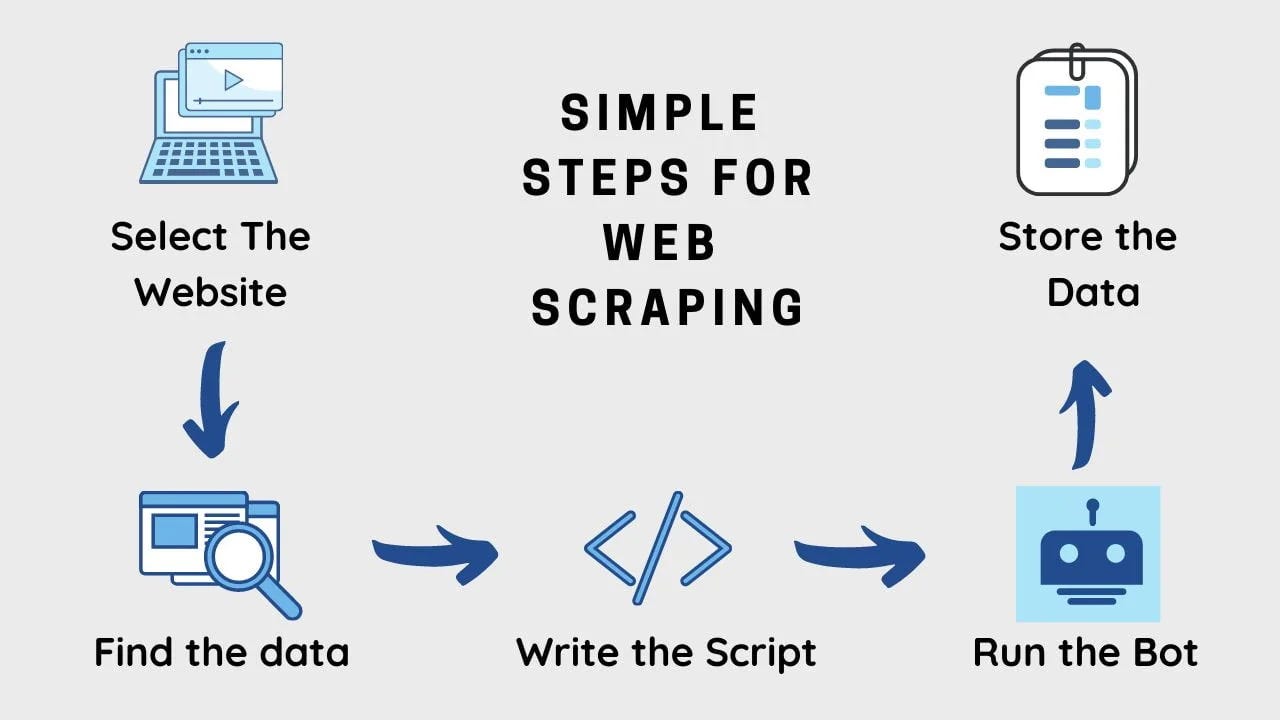
Let’s start with Web Crawling. Web crawling or spider crawling is a process, in which an automated program scours the web with the goal to collect and index as many webpages as possible. It will also try to index all possible pages of the website in order to index every possible piece of information. This is the process that most if not all Search Engines use in order to index their search results. Because of this, it is mostly in large quantities.
Web Scraping on the other hand is something that is akin to an extension of web crawling. With crawling, you find websites that are of interest, and you can then use Web Scraping software to extract information from the web page and downloading it.
Use Cases
There are many different use cases for Web Scraping, both in a personal or professional context. In a professional context, it can be utilized to gather valuable data from various fields:
- It is a tool that can be used to collect data for Machine Learning purposes. Without automation and tools, it would not be feasible to collect that amount of data
- In market research and competitive analysis, companies use Web Scraping to collect price information from competitors, analyse product trends, and monitor customer reviews.
- As mentioned, SEO and web analysis benefit from extracting data on search engine rankings, keyword density, and backlinks to enhance SEO strategies.
- Financial and economic data such as stock prices, exchange rates, or economic news can be extracted from public websites to support automated analysis or trading systems.
- Job and real estate portals employ Web Scraping to aggregate and analyse job postings or property listings from different websites.
It can also be used for a variety of personal use cases: - For example, it can be used for price tacking by extracting data from sites like Amazon or eBay
- The Availability of tickets for concerts or conferences could be scraped and tracked to be notified of them.
- News articles from a variety of new sites could be collected to read them later, especially by only scraping articles, that are of personal interest.
And many more use cases can exist for it.
Available Technologies
There are various tools available that focus on Web Scraping and allow users to start themselves. The right tool can be selected based on the needed complexity and size of the project. Python is a popular option to use for Web Scrapping because of the wide variety of available libraries and its ease of use. But there are also other options, for example for people without programming knowledge or ones that want a GUI.
Python:
- beautifulsoup4 · PyPI: A Python library that simplifies parsing HTML and XML data and ieterating through them.
- Selenium: It is not only exclusive to Python but can also be sued in a variety of other languages, like Java, Kotlin etc. It can be used for scraping dynamic websites that use JavaScript to load there content.
- Scrapy | A Fast and Powerful Scraping and Web Crawling Framework: A powerful framework for building web crawlers and scraping projects.
JavaScript/Node.js:
- Puppeteer: A Node.js library that drives Google Chrome or Chromium and is used for scraping JavaScript-loaded pages.
Other Tools:
- Web Scraping Tool & Free Web Crawlers | Octoparse: Octoparse is a visual Web Scraping tool for non-programmers.
- ParseHub | Free web scraping – The most powerful web scraper ParseHub is another tool that comes with a simple user interface.
Legal and Ethical Challenges
Since Web Scraping extracts the data and content from other users and businesses, there are important legal and ethical implications to think about
- One of the key legal concerns is privacy: data obtained through scraping may include personal information, which could potentially violate data protection laws such as the GDPR.
- Another significant issue is copyright: copying and publishing content without the owner’s permission can infringe upon copyright laws.
- Additionally, many websites have terms of use that prohibit scraping and circumventing these restrictions or IP blocks could lead to legal consequences.
Therefore, it is crucial to examine the legal framework before engaging in scraping and ensure that data is collected in an ethically responsible manner.
Programming Challenges

The other challenges one has to think about are the ones a programmer faces as well as the technical challenges that come with Web Scraping.
- Dynamic content is probably one of the biggest technical challenges. A lot of websites use JavaScript to change or create their content dynamically, which means just looking at the HTML and downloading it would mean that you lose out on valuable information. Specific tools, like Selenium or Puppeteer, can help work with dynamic content
- Some websites might want to prevent scraping. They can do this, for example, via captchas or by blocking certain IP addresses. There are technologies, like Captcha solvers or rotating the IP address, that can help with this.
- Somewhat connected to the last one, if you make a lot of requests to a certain webpage, they might think you have ill intentions and block your IP. Making too many requests could also lead to actual problems for the webpage owner, putting unnecessary load on their server.
- The web is always evolving, which means it is not uncommon for webpages to update their structure. This means that your script can sometimes stop working and need to be adjusted when web pages get updated.
These are just some of the possible challenges you could face.
Conclusion
Web Scraping is a valuable tool for extracting data from the internet in an automated way. It offers numerous applications, from market research to financial data analysis or personal projects. At the same time, developers have to consider the legal and ethical implications and overcome numerous technical challenges. Despite the challenges associated with Web Scraping, it remains an essential technique for collecting and processing web data.
Sources:
- Difference between Web Scraping and Web Crawling – GeeksforGeeks
- Know the Difference: Web Crawler vs Web Scraper
- 10 Web Scraping Challenges You Should Know – ZenRows
- 4 Web Scraping Challenges eCommerce Businesses Should Know About | Data-Entry-India | Blog
Image Sources: - Title Image: https://blog.stackademic.com/best-web-scraping-tools-in-2024-quick-guide-from-beginner-to-pro-3c3c799ca4ca
- Basics Image: https://medium.com/@pankaj_pandey/web-scraping-using-python-for-dynamic-web-pages-and-unveiling-hidden-insights-8dbc7da6dd26
- Challenges Image: https://www.data-entry-india.com/blog/4-web-scraping-challenges-ecommerce-businesses-should-know-about/

The comments are closed.