NLP Augmentation für Social-Media-Postings
Von Michelle Markl am 30.08.2022
Von April bis August 2022 durfte ich am Forschungsprojekt CounterSpeech (dt. Gegenrede) mitwirken. Das Projekt beschäftigt sich mit einer Methode, um Gegenrede in Social media Plattformen hervorzuheben, um so User*innen zu ermutigen Zivilcourage zu zeigen. Für dieses Ziel soll ein Machine Learning Konzept entwickelt werden, welches diese Gegenreden erkennt. Um das Modell bestmöglich zu trainieren, werden so viele Trainingsdaten wie möglich benötigt. Mit Hilfe einer passenden NLP Augmentation Library sollen Social-Media Einträge sinngemäß vervielfacht werden, um die Trainingsdaten für das Machine Learning Produkt zu vergrößern.
Vorbereitung
Im ersten Schritt, meiner Mitarbeit am Forschungsprojekt, habe ich mich mit den Grundbegriffen der Materie auseinandergesetzt.
NLP
Natural Language Processing (NLP) beschreibt Lösungen zur Verarbeitung von natürlicher Sprache (Luber, 2019). Mit Hilfe von Methoden aus den Sprachwissenschaften, kombiniert mit moderner Informatik soll Text, gesprochen oder geschrieben, erfasst und computerbasiert verarbeitet werden.
Hierbei bedient sich NLP an Methoden des Maschine Learnings, einem Teilbereich der Künstlichen Intelligenz (Luber, 2019). Es müssen Lösungen geschaffen werden, um die komplexe menschliche Sprache erkennen, analysieren und den Sinn extrahieren zu können. Die Herausforderung an die Methodik besteht darin komplexe Textzusammenhänge, Sachverhalte und Mehrdeutigkeit (Beispiele hierfür sind Ironie oder rhetorische Fragen) zu erkennen und richtig zu verarbeiten.
Anwendungsfelder, welche sich bereits finden lassen sind: Texte aus Dokumenten extrahieren, sprachgesteuerte Assistenten oder gesprochene Sprache in Echtzeit übersetzen (Luber, 2019).
Augmentation
Die Data Augmentation ist eine Technik, welche es ermöglicht Daten künstlich zu erhöhen (Tidke, 2022). Diese Methode wird verwendet, um das Problem zu weniger Trainingsdaten zu umgehen und um die Datendiversität zu erhöhen. Durch eine größere Trainingsdatenmenge, soll das Machine Learning Modell verbessert werden.
NLP Augmentation
Natural Language Processing Augmentation beschreibt somit Erweiterungstechniken für Textdaten. In dem Artikel, welchen ich für meine Recherche zur Verfügung bekommen habe, beschreibt Grg (2022) drei Techniken der Data Augmentation.
- Rule-Based: Easy Data Augmentation
- Example Interpolation Techniques: MIXUP, SEQ2MIXUP
- Model-Based: Seq2seq, language model, back translation, fine-tuning GPT-2, paraphrasing.
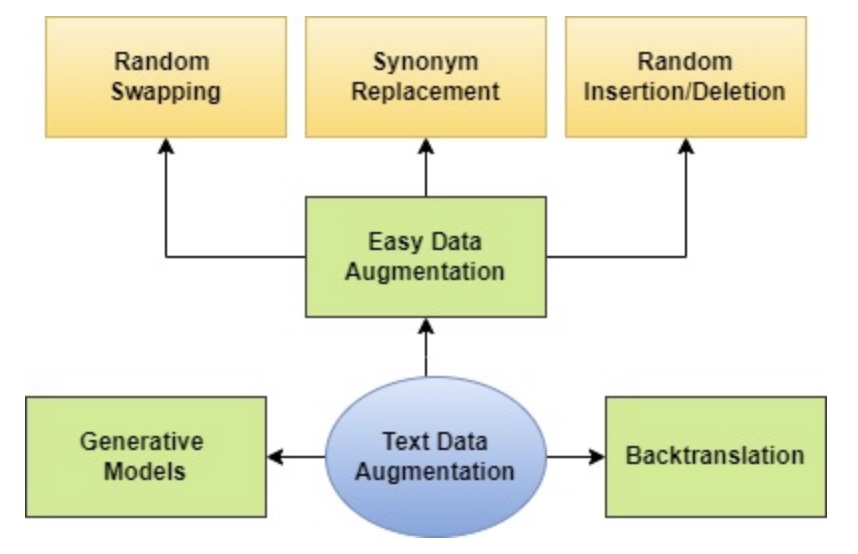
Easy Data Augmentation (EDA) ist die am häufigst verwendete Methode des regelbasierten Verfahren. Die Technik umfasst folgende Hauptaufgaben (Grg, 2022), auch auf Abb. 1 zu sehen:
- Synonym Replacement: Eine Anzahl an Wörter wird mit Synonymen ausgetauscht
- Random Deletion: Eine Anzahl an Wörtern wird aus dem Text gelöscht
- Random Swap: Zufällige zwei Wörter werden getauscht
- Random Insertion: Ein zufälliges Synonym eines Wortes des Texts wird in den Text eingefügt
Tidke (2022) führt weitere zwei Methoden der Datenerweiterung an: Generative Models und Backtranslation. Diese Erweiterungsmöglichkeiten können auf vier unterschiedlichen Ebenen eines Texts ausgeführt werden: (1) Zeichen, (2) Wort, (3) Phrase und (4) Dokument.
NLP Augmentation für Counter Speech Postings
Als Grundlage zur Recherche der NLP Augmentation Libraries dient der Blogeintrag von Grg (2022). Durch weitere Recherche im Bereich ist die Liste der Libraries um TextAttack erweitert worden. Die nachstehenden Libraries sind auf Aktualität und Methodenvielfalt analysiert worden.
Libraries sind:
- TextAugment
- AugLy
- Nlpaug
- Parrot Paraphrase
- Pegasus Paraphrase
- TextAttack
nlpaug und TextAttack sind in den folgenden Schritten näher für den Anwendungsbereich getestet worden. Als sinnvolle Methode für den Anwendungsfall ist die Augmentation Methode BackTranslation erachtet worden – die Libraries sind mit dieser Methode getestet worden.
BackTranslation
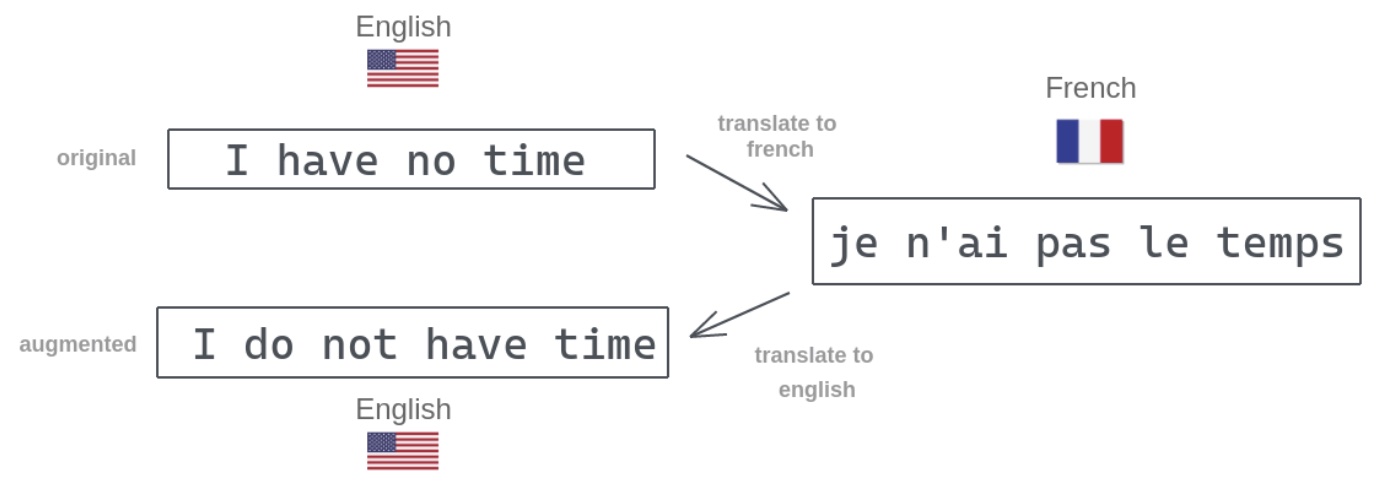
Anhand der Backtranslation Methode sollten die Libraries nlpaug und TextAttack verglichen werden. Neue Sätze werden entwickelt, indem ein Text in eine andere Sprache übersetzt wird, der neue Satz wird wieder zurück übersetzt, wie auf Abb. 2 zu erkennen ist (Tidke, 2022).
TextAttack
Das git-Repo für textattack finden Sie unter: https://github.com/QData/TextAttack
TextAttack bietet Lösungen für adversarial attacks, adversarial training und NLP Augmentation. Zum Testen der Augmentationfunktion ist die BackTranslation Methode herangezogen worden. Ein Projektspezifischer Testsatz dient als Input für die Methode, sowie die passenden Sprachmodelle von Hugging Face (https://huggingface.co) und den Abkürzung zur Sprachidentifikation, wie auf dem Codebeispiel zu sehen ist.
from textattack.transformations.sentence_transformations import BackTranslation
from textattack.constraints.pre_transformation import RepeatModification, StopwordModification
from textattack.augmentation import Augmenter
text = 'We are always developing as time goes on and same sex relationships are a part of the world now, why would we not educate our children on different ways of life?’
transformation = BackTranslation(
src_lang="en",
target_lang="es",
src_model="Helsinki-NLP/opus-mt-ROMANCE-en",
target_model="Helsinki-NLP/opus-mt-en-ROMANCE",
chained_back_translation=0,
)
constraints = [ RepeatModification(), StopwordModification() ]
augmenter = Augmenter(
transformation = transformation,
constraints = constraints
)
augmenter.augment(text)
Bei näherer Betrachtung der Dokumentation ist aufgefallen, dass für die zusätzlichen Sprachparameter eine Einschränkung besteht. Abb. 3 zeigt das Ergebnis des oberen Codebeispiels.

nlpaug
Das git-Repo für nlpaug finden Sie unter: https://github.com/makcedward/nlpaug
Nlpaug ist eine Library zur Textdatenerweiterung. Zum Testen der enthaltenen BackTranslation Methode ist das passende Code-Beispiel aus der Dokumentation herangezogen worden. Die Funktion ist mit einem für das Projekt relevanten Beispielsatz getestet worden. Der folgende Code Ausschnitt zeigt, wie die BackTranslation Methode aufgebaut ist.
import nlpaug.augmenter.word as naw
text = "We are always developing as time goes on and same sex relationships are a part of the world now, why would we not educate our children on different ways of life?"
back_translation_aug = naw.BackTranslationAug(
from_model_name="Helsinki-NLP/opus-mt-en-de",
to_model_name="Helsinki-NLP/opus-mt-de-en"
)
back_translation_aug.augment(text)
nlpaug bedient sich an den Sprachmodellen von Hugging Face (https://huggingface.co), ebenso wie TextAttack. Eine Funktion ist entwickelt worden, um unterschiedliche Sprachen schnell testen zu können, die unterschiedlichen Ergebnisse sind auf Abb. 4 abgebildet. Es ist zu erkennen, dass die Ergebnisse je nach Sprache sehr unterschiedlich ausfallen können. Trotz der unterschiedlichen Resultate, bleibt die Aussage des Postings gleich.

Fazit
Zusammenfassend bietet nlpaug mehr Freiheit im Sinne der Sprachmöglichkeiten, da die Methode dieser Library nur auf die Sprachmodelle von huggingface.com (Link nochmal nachschauen) beschränkt ist, Modelle beschriftet mit „Helsinki-NLP/“ . Im Vergleich zu nlpaug ist textattack hier durch weitere geforderte Sprachparameter beschränkt. Aus diesem Grund bietet nlpaug durch die unterschiedlichen Sprachmodelle eine höhere Datendiversität, was für das Projekt von Vorteil ist.
Quellen:
Grg, P. (2022, 5. März). NLP Data Augmentation – Pema Grg. Medium. Abgerufen am 29. März 2022, von https://pemagrg.medium.com/nlp-data-augmentation-a346479b295f
Luber, S. (2019, 19. März). Was ist Natural Language Processing? BigData-Insider. Abgerufen am 27. März 2022, von https://www.bigdata-insider.de/was-ist-natural-language-processing-a-590102/
Tidke, P. (2022, 26. Februar). Text Data Augmentation in Natural Language Processing with Texattack. Analytics Vidhya. Abgerufen am 28. März 2022, von https://www.analyticsvidhya.com/blog/2022/02/text-data-augmentation-in-natural-language-processing-with-texattack/
Titelbild: Bild von Gerd Altmann auf Pixabay

The comments are closed.