
Transfer Learning
Von Manuel Hecht am 03.03.2023
Natural Language Processing in Jupyter Notebooks mit FARM
Mit den jüngsten Fortschritten im auf Deep Learning basierenden NLP ist es einfacher denn je geworden, modernste Modelle auf Ihre eigenen Texte anzuwenden. In diesem Artikel stelle Ich euch die Methode des Transfer Learning vor.
Mit der fortschreitenden Digitalisierung von Unternehmen wächst die Datenmenge rasant. Während einige Daten in sorgfältig ausgewählten Formaten in hervorragend konstruierten relationalen Datenbanken gespeichert werden, handelt es sich bei den meisten tatsächlich um unstrukturierte Daten wie Text, Video und Bild. Das Sammeln von Informationen aus dieser Art von Dateien wurde erst in den letzten Jahren dank großer Fortschritte im Deep Learning möglich. Natural Language Processing (NLP) ist eine Disziplin im Bereich des maschinellen Lernens, die sich auf alle Arten von Textdaten konzentriert. Es ist heutzutage ein besonders spannendes Feld, weil wir wöchentlich neue Veröffentlichungen sehen, eine sehr aktive Open-Source-Community und gleichzeitig unzählige Möglichkeiten, NLP-Modelle in der realen Welt zu platzieren.
Transfer Learning: Den Weg vom Gewächshaus aufs Feld vereinfachen
Transfer Learning ist die Idee, an einer Art von Problem zu lernen (Pre-Training) und das erworbene Wissen auf ein neues Problem zu übertragen, wo es als Grundlage für weiteres verfeinertes Lernen verwendet werden kann (Fine-Tuning). Die Modelle können mit weniger Trainingsdaten an spezifische Geschäftsprobleme angepasst werden und erzielen sogar eine bessere Leistung. Diese Idee ist nicht neu und wurde erfolgreich auf viele Computer-Vision-Probleme angewendet.
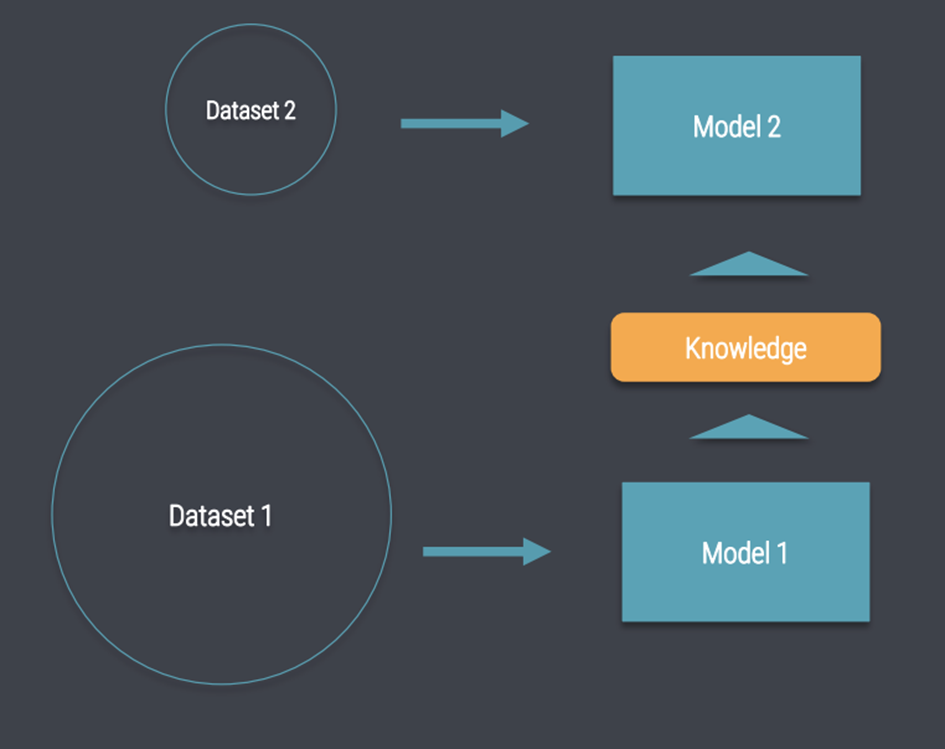
Das Transfer-Learning für NLP ist jedoch sehr herausfordernd, da das Modell das Erlernen eines grundlegenden, aber allgemeinen Sprachverständnisses erfordern würde. Aber wie können wir einem Computer beibringen, was ein Wort bedeutet? Diese Aufgabe ist zentral für das Gebiet des NLP, und seit ihrer Veröffentlichung waren word2vec und GloVe die Algorithmen der Wahl zur Generierung von Wortvektoren .In den letzten Jahren gab es eine ganze Reihe neuer Sprachmodelle, die genau dieses Problem angegangen sind und deren erlerntes Wissen auf nachgelagerte Aufgaben übertragen hat, was zu erheblichen Leistungsverbesserungen geführt hat.
Zum Glück gibt es ein paar Open-Source-Pakete, die Sie bei diesem Prozess unterstützen. Das ursprüngliche Tensorflow-Repository verfügt über verschiedene BERT-Modelle für verschiedene Sprachen und bietet grundlegende Skripte, um die Ergebnisse in der Arbeit zu replizieren. Der pytorch-pretrained-bert von Huggingface hat einige nette Ergänzungen, darunter mehr Modellarchitekturen, erweiterte Multi-GPU-Unterstützung und zusätzliche Skripte für die Feinabstimmung von Sprachmodellen. Sein Zweck ist jedoch immer noch eher die Replikation von Forschungsergebnissen und ein Ausgangspunkt für eigene Modelle. In dem Framework für Adapting Representation Models ( FARM ) soll das verwändert werden durch:
- einfache & schnelle Anpassung vortrainierter Modelle an Ihr Zielproblem
- leistungsstarke Protokollierung und Verfolgung von Modellen
- Persistierende Modellparameter und -konfigurationen für Reproduzierbarkeit
- einfache Visualisierung und Bereitstellung zur Präsentation Ihres Prototyps
Nachdem ich es für meine Bachelor-Arbeit sehr nützlich fand, entschied ich mich, es mit der euch zu teilen. Der Bau eucres eigenen hochmodernen Modells mit FARM erfordert nur wenige Schritte:
- 1) Wählt ein vortrainiertes Modell aus

- 2) Fügt einen Prediction-Head hinzu, der zu Ihrem Zielproblem passt

- 3) Erstellt einen Datenprocessor, der Ihre Dateien einliest und die Daten in das geeignete Format für das Modell konvertiert

- 4) Trainiert das Modell

In diesem Jupyter-Notebook gibt es von den Entwicklern ein eigenes Tutorial in einem Jupyter Notebook. Achtung, bei den Package-Dependencies wird es wahrscheinlich zu Problemen kommen…

The comments are closed.